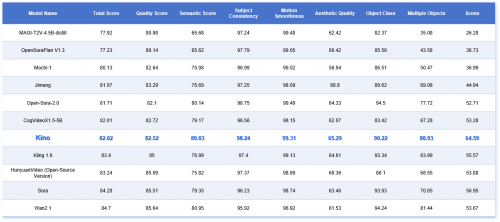
新一代自研AI视频模型Kino V2.2在全球权威测评平台vBench中以82.02综合得分跻身全球顶尖阵营,与Sora、Wan2.1等商业闭源模型同列TOP榜,并在关键维度力压Mochi、Open-Sora等开源竞品。

一、性能实测:多维度顶尖表现
在vBench实测中,Kino展现出对影视制作至关重要的三项核心能力:
复杂场景构建封王:64.59场景分(超开源模型均值37%),可稳定生成雨夜东京、丛林兽群等高动态环境;
多角色动态控制:80.93分实现群体运动精准调度,避免传统AI视频中常见的肢体错位;
电影级时序连贯:99.31运动平滑度比肩Sora,消除帧间撕裂卡顿,满足长镜头拍摄需求。
此外,还在主体一致性、美学质量、语义分数等多个维度上,取得与顶尖开源标杆模型和商业模型相当的表现。
vBench关键指标对比(精选TOP阵营)
二、成本革命:百万级实现技术核爆
在行业动辄千万训练成本的背景下,Kino团队交出震撼答卷:
3个月极速迭代:基于Kinov1.0的continue training高效升级
百万级成本破局:仅需100KH100 GPU小时
语料精炼革命:自研6层数据蒸馏管道,从海量素材中提纯1000小时黄金数据集,创新设计并基于Qwen2.5-VL-32B实现六维标注引擎,实现语义-视觉精准对齐
为提升Kino模型的可扩展性和训练效率,训练中应用了多种并行策略,根据硬件和数据动态调整,并优化了分布式训练;针对显存分配碎片问题,优化了动态内存分配策略,以防止显存不足并最大化GPU利用率。
三、三大技术引擎驱动影视级生成
Kino在行业保持领先地位源于其融合了三维变分自编码器(3D Variational Auto-Encoder, 3D VAE)与 Diffusion Transformer(DiT)架构,展现出卓越的时空建模能力与跨模态对齐。
Kino使用3D VAE技术压缩视频,将复杂视频数据映射到潜在空间。它通过动态调整patch大小来平衡压缩比和重建质量,优化信息保留。解码器将这些潜在表征还原成高质量视频。

人物动作表现human action

多物体处理能力multiple_objects
在视频生成主干中,Kino构建一个基于全注意力机制的Diffusion Transformer架构,融合双流(dual-stream)与单流(single-stream)处理模块。其中,双流模块分别独立建模文本与视觉模态,从而增强模态内语义特征;单流模块则通过跨模态注意力机制实现语义融合,对齐文本与视觉之间的语义,提升文本驱动下的视频生成精度与一致性。
此外,Kino在Transformer的注意力模块中引入3D RoPE,能够更有效捕捉帧间动态变化及空间结构特征,从而提升生成视频的时空一致性。在语义建模方面,Kino采用多语言预训练模型 umt5 对输入文本进行表征,增强模型对复杂语言结构的理解与泛化能力。同时,Kino融合多模态大模型作为辅助教师模型,通过跨模态语义对齐策略提升语言到视觉的映射质量,进一步增强生成视频在语义响应性与指令遵循方面的表现。
通过以上多维度优化,Kino在视频生成任务中展现出领先的时空连贯性、视觉逼真度与文本指令执行能力,适用于多场景的高质量视频生成应用。

Kino能力已覆盖从创意生成、分镜设计到多语言译制的影视全流程工业化生产,未来不仅是工具迭代,更是生产关系的重构。




《中国城市报》社有限公司版权所有,未经书面授权禁止使用
Copyright © 2015-2025 by www.zgcsb.com. all rights reserved